I have an interest in ways of defining APIs that useful and easily shared between development, documentation and testing. I’ve been working on the Pacto contract-testing project for a while, and more recently I was a member of the working group for the Swagger 2.0 release.
Pacto itself will be switching to Swagger contracts in the near future. I plan to put out a v0.4.0 release that has initial support for Swagger and deprecates the current contract format, followed by v0.5.0 release with more complete Swagger support and that makes Swagger 2.0 the default contract format.
I’ve recently hacked together a few open-source projects related to that effort.
Swagger.rb
I’m releasing a Swagger parser for Ruby. The goals are:
- Structurally and semantically validate Swagger documents (just like swagger-tools)
- Load Swagger documents
- Provide a “flatter” API for iterating over Swagger’s hierarchical structure
- Provide a builder to create Swagger contracts from other data
Note: I’ve named the gem swagger-core, because there is already a gem called swagger (which is not related to the Swagger project).
Source: https://github.com/swagger-rb/swagger-rb
Swagger CLI
I’ve been working on a CLI tool that use the Swagger parser. The initial action I’m working on is a code generator that’s based on Thor, the same framework used by Rails and Padrino generators, and by the Middleman static site generator. So this is also a proof of concept of how the Swagger parser could be integrated with those frameworks. Right now there is a template available for Grape, and I’ve also experimented with generating scripts to load a Mongo database for Pitchfork.
In the future I’ll probably add actions to validate, upgrade, or test Swagger APIs.
Source: https://github.com/swagger-rb/swagger-cli
wadl2swagger
I’ve been playing around with the OpenStack services, which are all defined using WADL. I wanted to be able equivalent Swagger to start playing around with, so I created a tool that converts from WADL to Swagger.
It does try to do a straightforward WADL->Swagger conversion whenever there is an equivalent concept, but many of the Swagger concepts don’t exist in the WADL standard. Sometimes it converts based on the conventions being followed in OpenStack WADLs, which include a mix of WADL and docbook. For example, WADL does not define a way to include example request/response data, but OpenStack documents this using docbook programlistings. So wadl2swagger will try to find these programlistings and convert them to Swagger example objects.



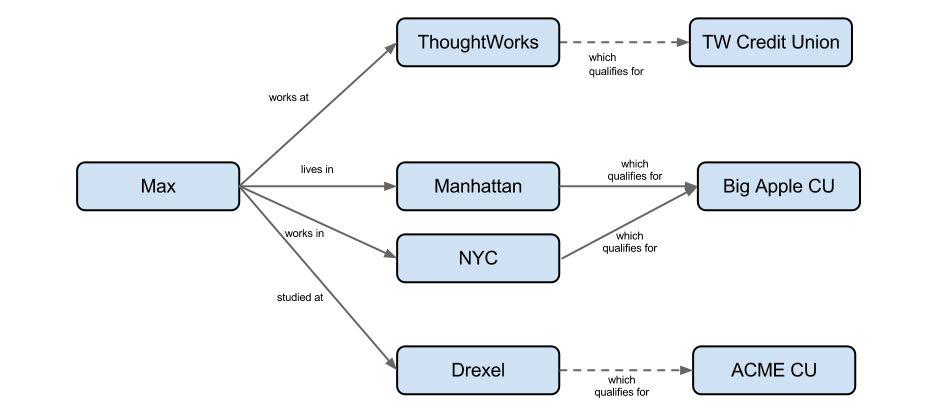 This graph contains two unconditional qualifications and two conditional qualifications. The two conditions (not shown) could be different.
This graph contains two unconditional qualifications and two conditional qualifications. The two conditions (not shown) could be different.

